1.STL简单介绍
(1)标准模版库,是C++里面的标准库的一部分,C++标准库里面还有其他的东西,但是我们不经常使用,我们经常使用的还是STL这个标准库部分。
(2)六大件:仿函数,算法,迭代器,空间配置器,容器,配接器;
2.string标准库
(1)string这个里面包含100多个函数,这个总体的设计还是比较复杂的;
(2)下面浅浅的使用string感受一下这个基本的使用和他的便捷性;
string里面有不传参的构造函数和传参的构造函数,我们可以简单的定义试用一下:

s1就是我们定义的不传参的对象,s2就是传参的对象;
(3)string里面已经重载+这个运算符,所以我们可以实现不同对象的相加,以及我们创建的对象和字符串的相加;

这些都是可以实现的,相比于C语言里面的strcat函数,虽然也是可以实现这个功能的,但是使用起来没有C++里面的string这个方便,因为C语言里面实现这个字符串的相加需要找到斜杠0,再去追加,而且要考虑会不会溢出的问题,因为我们追加的字符串可能超过原本的字符串的大小,这些都是我们需要考虑的问题 ,但是使用string就不需要考虑这些问题,因为系统会自动扩容;
(4)带参数的构造的两种形式

这两种方式最后可以达到的效果是一样的,第二种本质上就是构造加拷贝构造加优化,因为单参数的支持类型的转换;
3.使用string进行遍历的三种方式
(1)就是我们最熟悉的使用循环进行遍历:这个过程是可读可写的,第一种就是便利这个字符串里面的每个字符,size这个函数就是string里面已经实现的函数,我们是可以直接进行使用的,这个函数的作用就是求这个字符串的长度;
我们在这个循环里面还是用了[ ]这样的成员访问运算符,这个实际上string作为类肯定是不能直接进行访问的(因为这个我们之前已经在运算符重载的时候介绍过),这些运算符是针对的内置类型,类这样的自定义类型也是不能直接使用的,要想使用就必须进行运算符的重载,但是string的库里面已经实现了,所以我们也是可以直接使用的

(2)使用迭代器进行遍历:
下面我们分别使用正向的迭代器和反向的迭代器进行这个字符串的结果的打印;

迭代器和指针很相似,我们想要实现这个字符串的遍历,就要找到字符串的头部位置,begin这个函数就可以找到这个字符串的头部的位置,end这个函数就可以找到这个字符串的尾部的位置;
我们是使用string这个类创建对象,并且使用的是有参的初始化,string::iterator就是正向的迭代器的格式,这个里面定义的it相当于是一个形参这个名字是可以随便写的,但是前面的那个是不可以修改的(前面的是正向的迭代器的固定书写格式),我们的it就相当于是一个指针,我们我们是使用循环,对这个it进行解引用之后打印的,每次打印之后都会让这个it++,我们的循环条件写的是it!=s1.end()就是只用it没有指向这个字符串的最后一个字符,我们就不会停止打印;
这里的循环条件其实也是可以选择it<s1.end()这个其实也是符合的,也是可以作为循环条件的,但是我们这里使用的是不等于,因为这个不等于更具有普适性,就是我们这里学习string可以使用,我们将来学习vector和list也是可以使用的,这个具有通用性,但是像那个小于号作为循环的条件的话,在其他的情况下面就会报错,不具有普适性,所以我们推荐的是it!=s1.end()这样的写法;
上面的是正向的迭代器,下面我们可以看一下反向的迭代器和它的作用,使用的方法;

有下面的几点需要我们注意:
(1)反向迭代器前面的string_reverse_iterator也是固定的,这个我们是不能乱写的,但是后面的it我们是可以进行其他名字的定义;
(2)我们在正向迭代器里面使用的函数就是begin()函数和end()函数,在这个反向的迭代器里面,我们使用的函数和正向迭代器的函数的作用是一样的,但是在函数的名字上面进行了修饰,就是为了进行区分,在这个函数的名字前面加上了r(就是reverse的首个字母);
(3)我们这里的s3.rbegin()这个函数的调用之后,拿到的是这个字符串的最后一个字符,所以我们称之为反向迭代器,it++是向前加加,所以我们在使用反向迭代器的时候是从后向前看的,这个时候打印出来的结果就是按照从后向前的顺序进行打印的;
(4)这个里面,我们就可以重新认识一下auto这个关键字的功能了,这里我们写的string::reverse_iterator这个类型的名字就会比较长,比较繁琐,我们就可以使用这个auto关键字进行替代,auto这个关键字的作用就是对于这个函数的返回值类型进行自动的识别,这里的rbegin函数的返回值就是string::reverse_iterator类型的(详情请阅读下面的文档),我们替换之后啊这个编译器就会自动的匹配类型,这样是同样可以是像我们想要的效果的;


(3)使用范围for进行打印结果

从语法上面来讲,这个范围for是很强的,因为我们不需要进行其他的额外操作,这个范围for使用的时候编译器会自动的进行加加操作,自动的判断结束,使用的格式就是上面的展示那样;
但是这个范围for这个语法本质上面和迭代器是没有本质的区别的,范围for和迭代器在底层上面是很类似的,其实也并不是什么高大上的东西;
(4)const修饰的迭代器

这个时候编译器就会报错,就是因为这个const导致的权限的问题,我们是需要进行下面的修改的

就是我们这里是使用带const的形参进行调用这个begin函数的,形参s是const类型的,我们的返回值就应该进行一定的程度的修改;
实际上,我们的这个begin函数是有两种返回值的类型的,一种是带const的,另外的一种是不带const的,我们只需要注意在适应的时候相互对应就可以了;
这里是列举了正向迭代器带const的版本,反向的一样的,const添加的位置就是下面的图片展示的那样,注意这个const添加的位置(不要加在最前面);

(5)总结:通过这个对于字符串进行遍历,我们引入了迭代器这个概念,这个迭代器在严格的意义上面是有4种的,带const的正向迭代器,不带const的正向迭代器,带const的反向迭代器,不带const的反向迭代器,并对部分进行了展示;
虽然迭代器看似很好,但是我们不会经常使用,因为这个string 里面重载了[ ]运算符的,我们是可以直接使用这个运算符进行访问的,但是我们学习这个迭代器是因为这个迭代器在vertor以及list里面均有涉及到,我们要大致的认识了解。
4.一些其他的函数说明
(1)拷贝和选择性拷贝
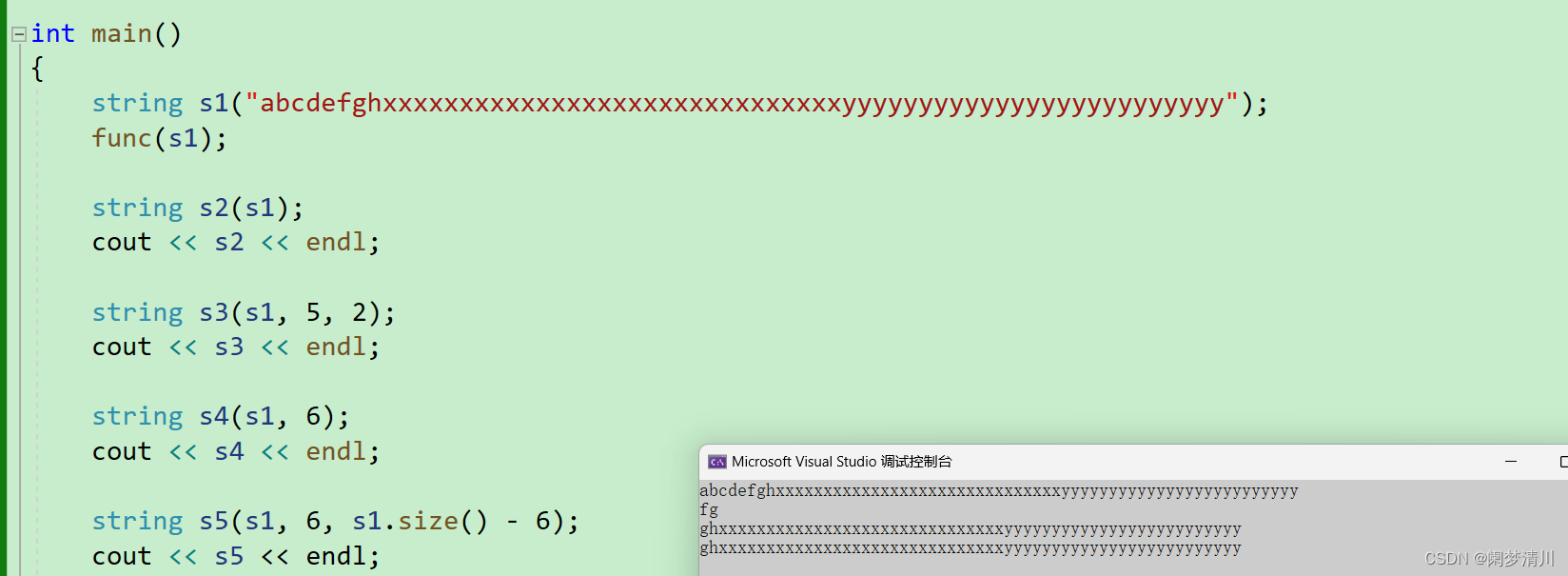
 这里的s2就是s1的直接全部拷贝,s3就是从s1的下标为5的字符位置处开始拷贝,拷贝的数量就是2个字符(这个函数里面的每个参数的实际含义我们也是应该了解的);
这里的s2就是s1的直接全部拷贝,s3就是从s1的下标为5的字符位置处开始拷贝,拷贝的数量就是2个字符(这个函数里面的每个参数的实际含义我们也是应该了解的);
我们这个里面的三个参数第一个就是我们想要拷贝的对象,第二个就是我们想要拷贝的字符的起始位置,第三个就是我们想要拷贝的终止位置;
如果我们想要拷贝到最后一个数据,难道我们要一个一个数吗?肯定是不需要的,我们可以有两种解决方案,一种就是直接不写第三个参数,因为就算我们不写,其实这个也是有默认的缺省参数的,我们不写的话,这个第三个参数就会直接默认是最后的一个字符;
我们是有方法去求解这个后面字符的个数的,我们可以调用这个size函数求解全部的字符的个数再去减去第二个参数,这样的话也是可以求得这个后面的字符的个数的;
(2)初始化的相关函数

这里的话就是使用的10个a进行初始化,下面的那种是使用的一段区间进行初始化;
(3)求字符串的长度的函数

这两个函数都可以求解字符串的长度,但是好像并没有区别,为什么会出现两个用途一样的函数?因为string的出现时间比STL更早,本来使用的是length函数求解字符串的长度,后来STL出现之后,就添加了size函数,这个size函数更加通用,使用更加广泛;
5.string的一个简单的应用

(1)下面我们使用string的相关语法和函数进行求解:

(2)因为这个里面出现的都是26个字母,所以我们就可以定义一个26个字符大小的一个数组,用来存储数据,接下来使用迭代器进行遍历,统计次数,ch为什么要减去‘a’,这个地方实际上就是ASCII值的相关计算,假设我们的a字符,ASCII是97,我们这个时候拿97作为这个数组的下标肯定是会越界的,我们需要找到一个相对的下标,就是使用这个ch-a相当于是减去97作为这个数组的下标;
(3)上面的这个迭代器完成之后,我们就已经统计出来了26个字母,每个字母在这个字符串里面出现的次数,接下来我们就要查看哪个字符出现一次,而且我们要找的是第一个只出现一次的字符,找到之后就返回这个下标,否则就返回-1。